The Challenge of Large File Checksums


How often do you use a website's provided checksum to verify that a file you downloaded wasn't corrupted or worse, what if it was tampered with during a man in the middle attack?
In the modern day of internet, I suppose you won't be using the checksum values on the website to make sure these things doesn't happen. Since we just all assume that the download is correct and if not we will just press the download button again.
We are shielded from these issues most of the time as we often relay on data transfer protocols to guarantee packet delivery.
Well, as a person who have too much time on their hand sometimes, I like to use the checksum function to make sure what I'm downloading is what the vendors share.
Every time when I try to use run checksum on large files over a few Gigabyte large, it started to feel slow, takes a few extra second than normal. So I decided I needed to take this issue into my own hand, and save myself a few extra second.
What is Merkle Tree
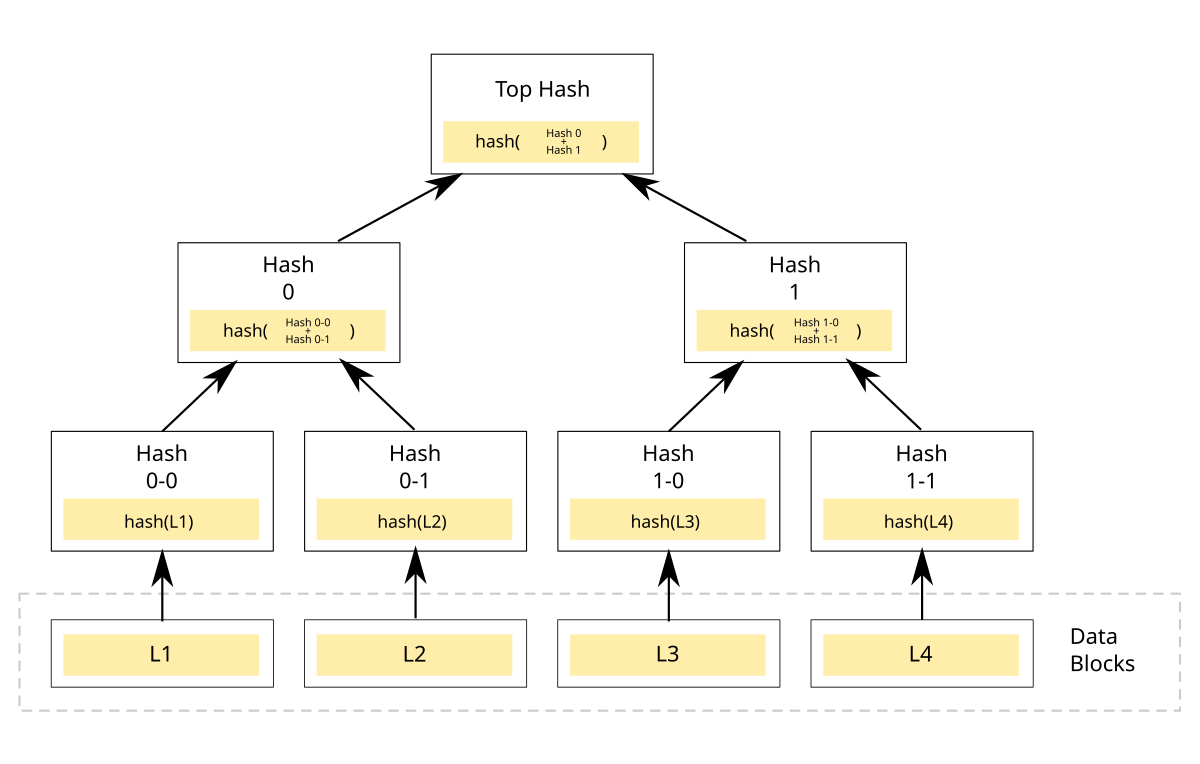
A Merkle Tree is when you try to compute a hash object though a tree like structure:
https://en.wikipedia.org/wiki/Merkle_tree
In this case you will be chopping up the files into chunks or data blocks, which you can individually hash them creating the leaf node of the tree.
Which than you can build upon the leaf nodes by hashing each data blocks with it's neighbor. Repeating the process recursively and it will build into a full Merkle tree
Here is what it will look like:
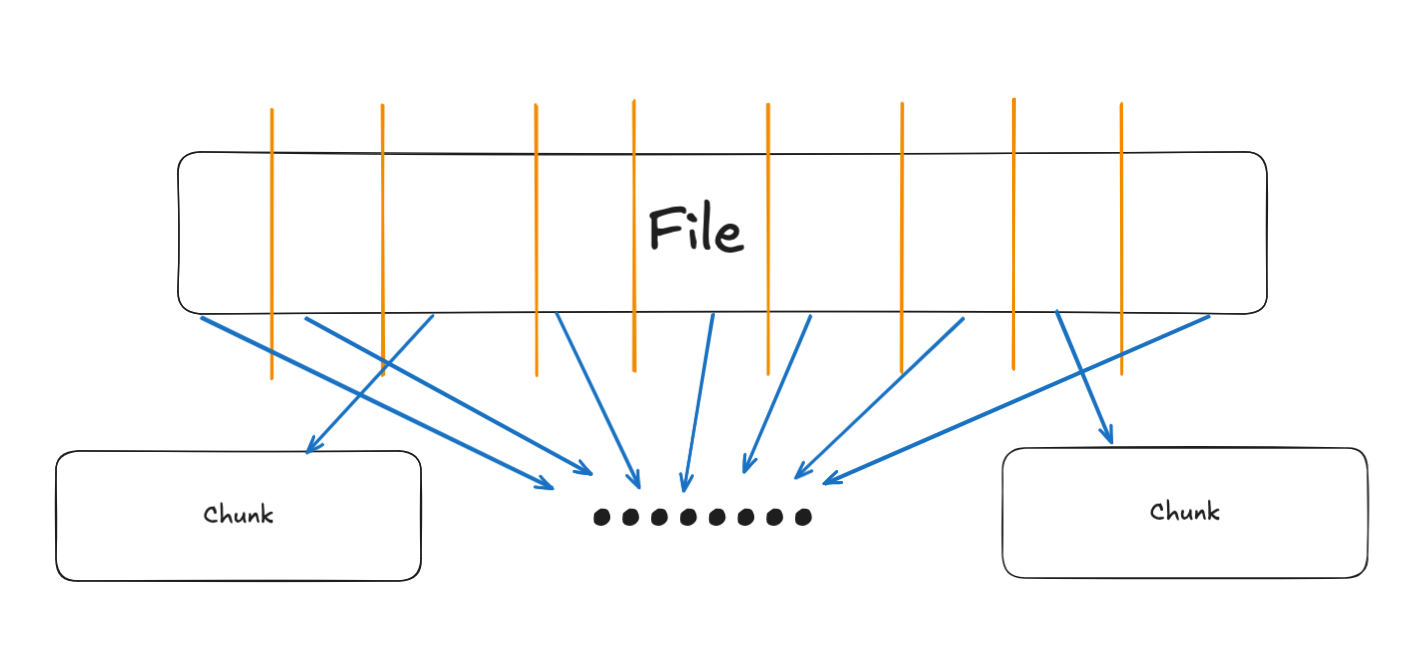
- Spiting the large file into chunks
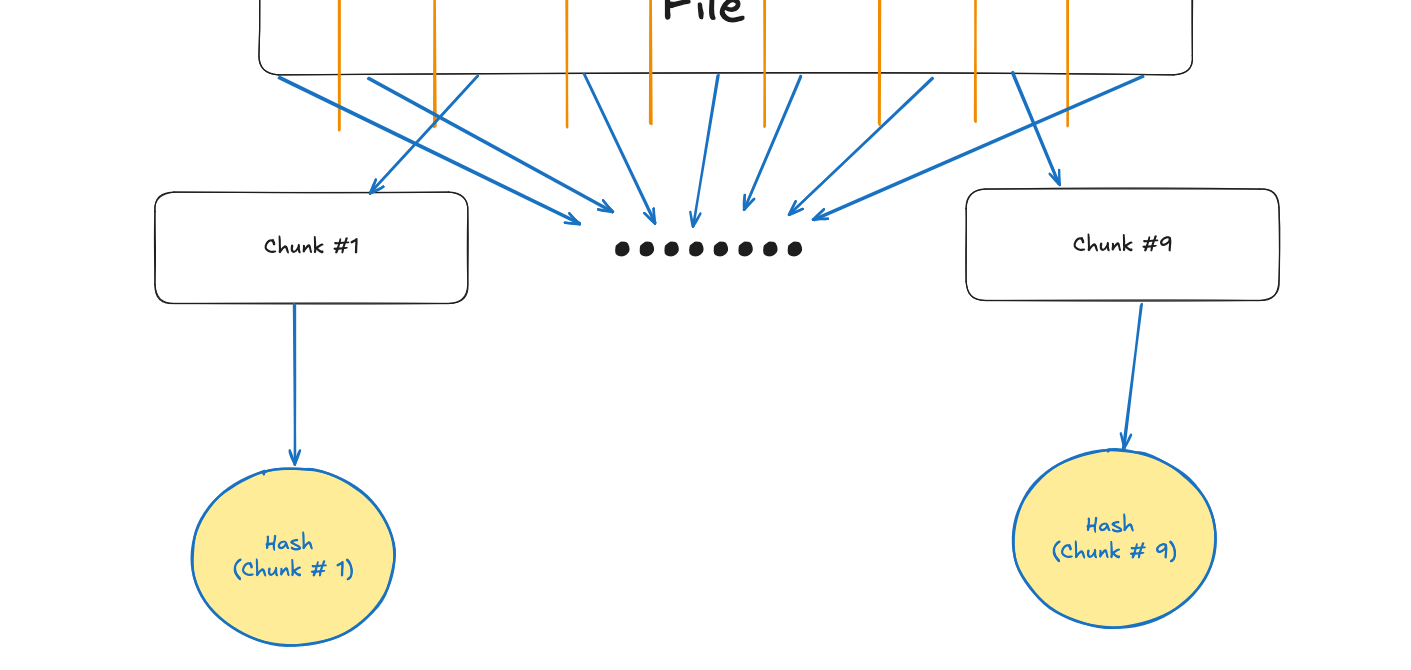
- Computer hash of each file chunk
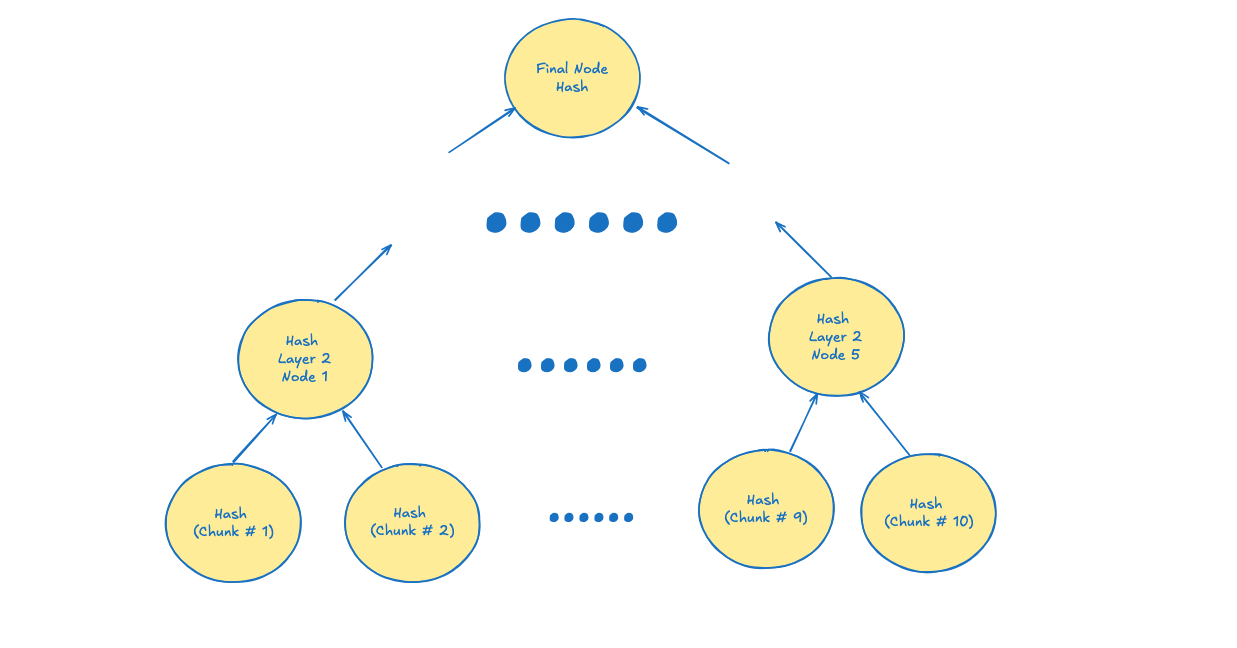
- Computing hash of the next layer continuously until final node is reached
Here is a concurrent Merkle Tree program I wrote in Golang:
When writing this program, I was trying to decide if I should use the fork-join method to hash the nodes concurrently, or if I should implement a pipeline method, where each level of the tree would be handled by a separate thread, responsible for hashing the nodes at that level until reaching the final level (root).
I ultimately went with the pipeline method because I had a few other ideas I wanted to work on, and the pipeline approach seemed more straightforward to implement.
Reference: